import pandas as pd
import numpy as np
import sqlite3
from plotnine import *
from mizani.formatters import percent_format
from itertools import product
from joblib import Parallel, delayed, cpu_countSize Sorts and p-Hacking
Note
You are reading Tidy Finance with Python. You can find the equivalent chapter for the sibling Tidy Finance with R here.
In this chapter, we continue with portfolio sorts in a univariate setting. Yet, we consider firm size as a sorting variable, which gives rise to a well-known return factor: the size premium. The size premium arises from buying small stocks and selling large stocks. Prominently, Fama and French (1993) include it as a factor in their three-factor model. Apart from that, asset managers commonly include size as a key firm characteristic when making investment decisions.
We also introduce new choices in the formation of portfolios. In particular, we discuss listing exchanges, industries, weighting regimes, and periods. These choices matter for the portfolio returns and result in different size premiums Walter, Weber, and Weiss (2022). Exploiting these ideas to generate favorable results is called p-hacking. There is arguably a thin line between p-hacking and conducting robustness tests. Our purpose here is to illustrate the substantial variation that can arise along the evidence-generating process.
The chapter relies on the following set of Python packages:
Compared to previous chapters, we introduce itertools, which is a component of the Python standard library and provides fast, memory-efficient tools for working with iterators.
Data Preparation
First, we retrieve the relevant data from our SQLite database introduced in Accessing and Managing Financial Data and WRDS, CRSP, and Compustat. Firm size is defined as market equity in most asset pricing applications that we retrieve from CRSP. We further use the Fama-French factor returns for performance evaluation.
tidy_finance = sqlite3.connect(
database="data/tidy_finance_python.sqlite"
)
crsp_monthly = pd.read_sql_query(
sql="SELECT * FROM crsp_monthly",
con=tidy_finance,
parse_dates={"date"}
)
factors_ff3_monthly = pd.read_sql_query(
sql="SELECT * FROM factors_ff3_monthly",
con=tidy_finance,
parse_dates={"date"}
)Size Distribution
Before we build our size portfolios, we investigate the distribution of the variable firm size. Visualizing the data is a valuable starting point to understand the input to the analysis. Figure 1 shows the fraction of total market capitalization concentrated in the largest firm. To produce this graph, we create monthly indicators that track whether a stock belongs to the largest x percent of the firms. Then, we aggregate the firms within each bucket and compute the buckets’ share of total market capitalization.
Figure 1 shows that the largest 1 percent of firms cover up to 50 percent of the total market capitalization, and holding just the 25 percent largest firms in the CRSP universe essentially replicates the market portfolio. The distribution of firm size thus implies that the largest firms of the market dominate many small firms whenever we use value-weighted benchmarks.
market_cap_concentration = (crsp_monthly
.groupby("date")
.apply(lambda x: x.assign(
top01=(x["mktcap"] >= np.quantile(x["mktcap"], 0.99)),
top05=(x["mktcap"] >= np.quantile(x["mktcap"], 0.95)),
top10=(x["mktcap"] >= np.quantile(x["mktcap"], 0.90)),
top25=(x["mktcap"] >= np.quantile(x["mktcap"], 0.75)))
)
.reset_index(drop=True)
.groupby("date")
.apply(lambda x: pd.Series({
"Largest 1%": x["mktcap"][x["top01"]].sum()/x["mktcap"].sum(),
"Largest 5%": x["mktcap"][x["top05"]].sum()/x["mktcap"].sum(),
"Largest 10%": x["mktcap"][x["top10"]].sum()/x["mktcap"].sum(),
"Largest 25%": x["mktcap"][x["top25"]].sum()/x["mktcap"].sum()
})
)
.reset_index()
.melt(id_vars="date", var_name="name", value_name="value")
)
market_cap_concentration_figure = (
ggplot(
market_cap_concentration,
aes(x="date", y="value", color="name", linetype="name")
)
+ geom_line()
+ scale_y_continuous(labels=percent_format())
+ scale_x_date(name="", date_labels="%Y")
+ labs(
x="", y="", color="", linetype="",
title="Percentage of total market capitalization in largest stocks"
)
+ theme(legend_title=element_blank())
)
market_cap_concentration_figure.show()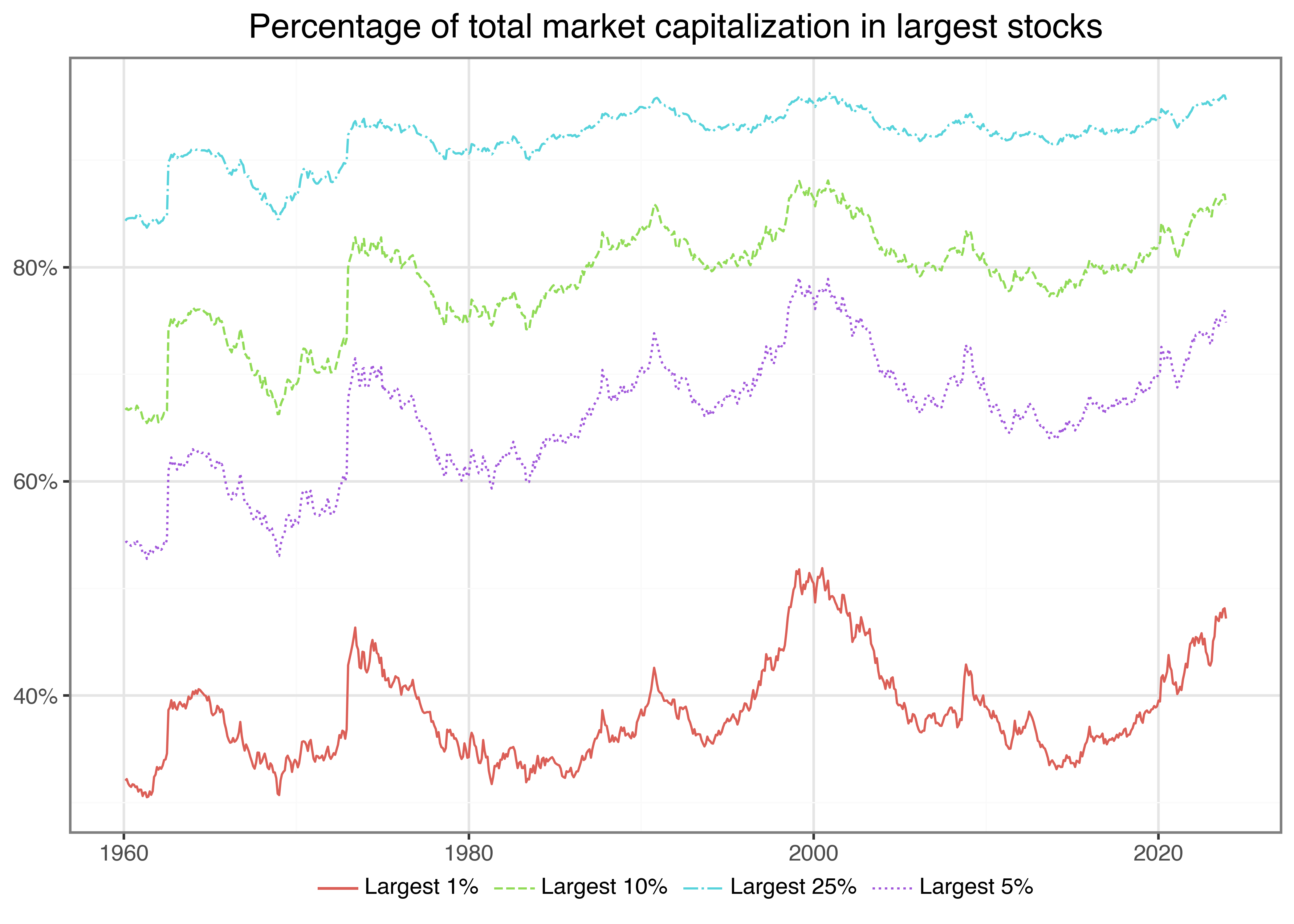
Next, firm sizes also differ across listing exchanges. The primary listings of stocks were important in the past and are potentially still relevant today. Figure 2 shows that the New York Stock Exchange (NYSE) was and still is the largest listing exchange in terms of market capitalization. More recently, NASDAQ has gained relevance as a listing exchange. Do you know what the small peak in NASDAQ’s market cap around the year 2000 was?
market_cap_share = (crsp_monthly
.groupby(["date", "exchange"])
.aggregate({"mktcap": "sum"})
.reset_index(drop=False)
.groupby("date")
.apply(lambda x:
x.assign(total_market_cap=lambda x: x["mktcap"].sum(),
share=lambda x: x["mktcap"]/x["total_market_cap"]
)
)
.reset_index(drop=True)
)
plot_market_cap_share = (
ggplot(market_cap_share,
aes(x="date", y="share",
fill="exchange", color="exchange")) +
geom_area(position="stack", stat="identity", alpha=0.5) +
geom_line(position="stack") +
scale_y_continuous(labels=percent_format()) +
scale_x_date(name="", date_labels="%Y") +
labs(x="", y="", fill="", color="",
title="Share of total market capitalization per listing exchange") +
theme(legend_title=element_blank())
)
plot_market_cap_share.draw()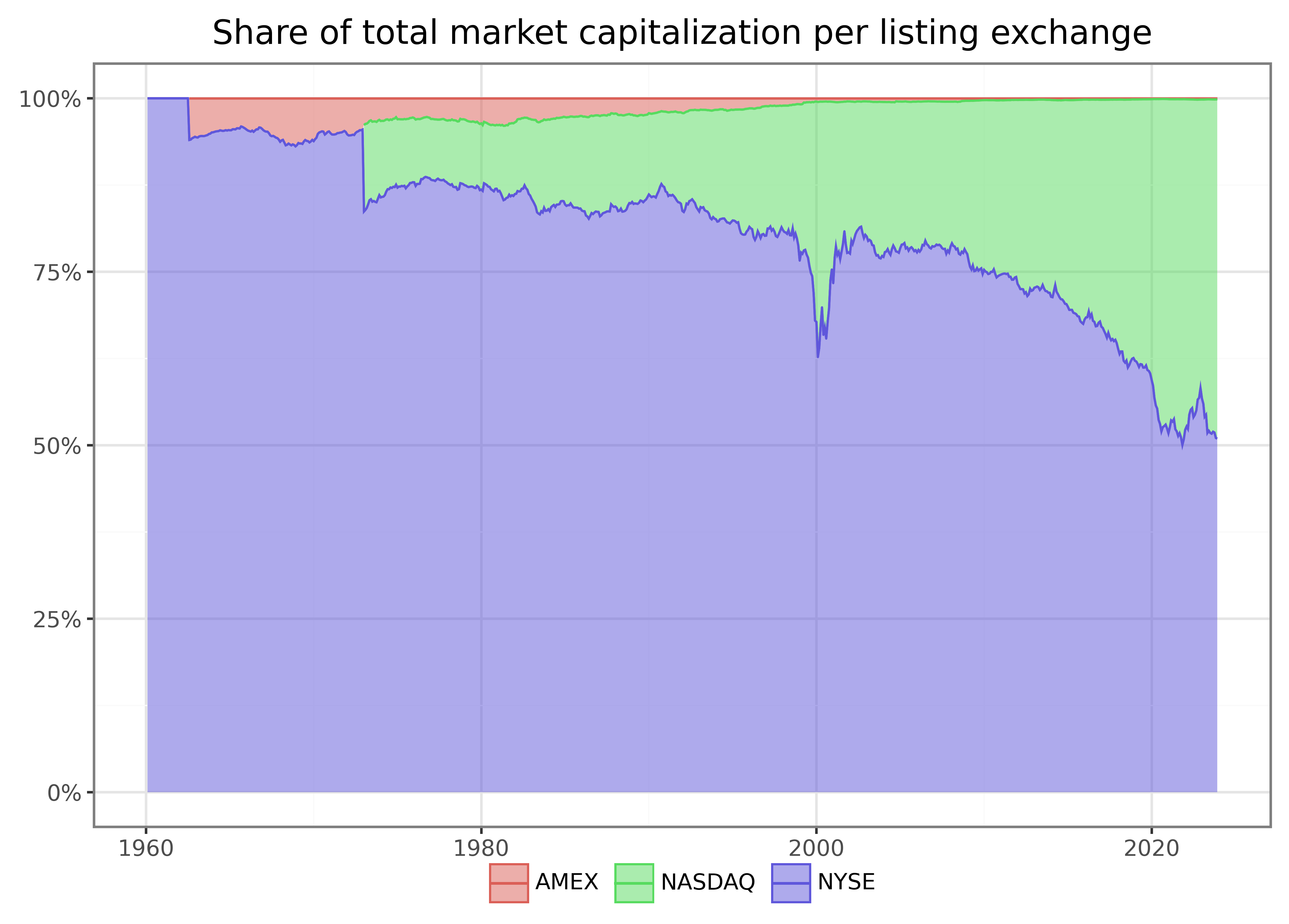
Finally, we consider the distribution of firm size across listing exchanges and create summary statistics. The function describe() does not include all statistics we are interested in, which is why we create the function compute_summary() that adds the standard deviation and the number of observations. Then, we apply it to the most current month of our CRSP data on each listing exchange. We also add a row with the overall summary statistics.
The resulting table shows that firms listed on NYSE in December 2021 are significantly larger on average than firms listed on the other exchanges. Moreover, NASDAQ lists the largest number of firms. This discrepancy between firm sizes across listing exchanges motivated researchers to form breakpoints exclusively on the NYSE sample and apply those breakpoints to all stocks. In the following, we use this distinction to update our portfolio sort procedure.
def compute_summary(data, variable, filter_variable, percentiles):
"""Compute summary statistics for a given variable and percentiles."""
summary = (data
.get([filter_variable, variable])
.groupby(filter_variable)
.describe(percentiles=percentiles)
)
summary.columns = summary.columns.droplevel(0)
summary_overall = (data
.get(variable)
.describe(percentiles=percentiles)
)
summary.loc["Overall", :] = summary_overall
return summary.round(0)
compute_summary(
crsp_monthly[crsp_monthly["date"] == crsp_monthly["date"].max()],
variable="mktcap",
filter_variable="exchange",
percentiles=[0.05, 0.5, 0.95]
)| count | mean | std | min | 5% | 50% | 95% | max | |
|---|---|---|---|---|---|---|---|---|
| exchange | ||||||||
| AMEX | 166.0 | 422.0 | 3182.0 | 1.0 | 4.0 | 47.0 | 850.0 | 40673.0 |
| NASDAQ | 2556.0 | 8920.0 | 97176.0 | 0.0 | 6.0 | 263.0 | 16817.0 | 2976557.0 |
| NYSE | 1289.0 | 18432.0 | 51240.0 | 13.0 | 120.0 | 3515.0 | 77878.0 | 553370.0 |
| Overall | 4011.0 | 11625.0 | 82977.0 | 0.0 | 8.0 | 601.0 | 40704.0 | 2976557.0 |
Univariate Size Portfolios with Flexible Breakpoints
In Univariate Portfolio Sorts, we construct portfolios with a varying number of breakpoints and different sorting variables. Here, we extend the framework such that we compute breakpoints on a subset of the data, for instance, based on selected listing exchanges. In published asset pricing articles, many scholars compute sorting breakpoints only on NYSE-listed stocks. These NYSE-specific breakpoints are then applied to the entire universe of stocks.
To replicate the NYSE-centered sorting procedure, we introduce exchanges as an argument in our assign_portfolio() function from Univariate Portfolio Sorts. The exchange-specific argument then enters in the filter data["exchanges"].isin(exchanges). For example, if exchanges='NYSE' is specified, only stocks listed on NYSE are used to compute the breakpoints. Alternatively, you could specify exchanges=["NYSE", "NASDAQ", "AMEX"], which keeps all stocks listed on either of these exchanges.
def assign_portfolio(data, exchanges, sorting_variable, n_portfolios):
"""Assign portfolio for a given sorting variable."""
breakpoints = (data
.query(f"exchange in {exchanges}")
.get(sorting_variable)
.quantile(np.linspace(0, 1, num=n_portfolios+1),
interpolation="linear")
.drop_duplicates()
)
breakpoints.iloc[[0, -1]] = [-np.Inf, np.Inf]
assigned_portfolios = pd.cut(
data[sorting_variable],
bins=breakpoints,
labels=range(1, breakpoints.size),
include_lowest=True,
right=False
)
return assigned_portfoliosNote that the tidyfinance package also provides a assing_portfolio() function, albeit with more flexibility. For the sake of simplicity, we continue to use the function that we just defined.
Weighting Schemes for Portfolios
Apart from computing breakpoints on different samples, researchers often use different portfolio weighting schemes. So far, we weighted each portfolio constituent by its relative market equity of the previous period. This protocol is called value-weighting. The alternative protocol is equal-weighting, which assigns each stock’s return the same weight, i.e., a simple average of the constituents’ returns. Notice that equal-weighting is difficult in practice as the portfolio manager needs to rebalance the portfolio monthly, while value-weighting is a truly passive investment.
We implement the two weighting schemes in the function compute_portfolio_returns() that takes a logical argument to weight the returns by firm value. Additionally, the long-short portfolio is long in the smallest firms and short in the largest firms, consistent with research showing that small firms outperform their larger counterparts. Apart from these two changes, the function is similar to the procedure in Univariate Portfolio Sorts.
def calculate_returns(data, value_weighted):
"""Calculate (value-weighted) returns."""
if value_weighted:
return np.average(data["ret_excess"], weights=data["mktcap_lag"])
else:
return data["ret_excess"].mean()
def compute_portfolio_returns(n_portfolios=10,
exchanges=["NYSE", "NASDAQ", "AMEX"],
value_weighted=True,
data=crsp_monthly):
"""Compute (value-weighted) portfolio returns."""
returns = (data
.groupby("date")
.apply(lambda x: x.assign(
portfolio=assign_portfolio(x, exchanges,
"mktcap_lag", n_portfolios))
)
.reset_index(drop=True)
.groupby(["portfolio", "date"])
.apply(lambda x: x.assign(
ret=calculate_returns(x, value_weighted))
)
.reset_index(drop=True)
.groupby("date")
.apply(lambda x:
pd.Series({"size_premium": x.loc[x["portfolio"].idxmin(), "ret"]-
x.loc[x["portfolio"].idxmax(), "ret"]}))
.reset_index(drop=True)
.aggregate({"size_premium": "mean"})
)
return returnsTo see how the function compute_portfolio_returns() works, we consider a simple median breakpoint example with value-weighted returns. We are interested in the effect of restricting listing exchanges on the estimation of the size premium. In the first function call, we compute returns based on breakpoints from all listing exchanges. Then, we computed returns based on breakpoints from NYSE-listed stocks.
ret_all = compute_portfolio_returns(
n_portfolios=2,
exchanges=["NYSE", "NASDAQ", "AMEX"],
value_weighted=True,
data=crsp_monthly
)
ret_nyse = compute_portfolio_returns(
n_portfolios=2,
exchanges=["NYSE"],
value_weighted=True,
data=crsp_monthly
)
data = pd.DataFrame([ret_all*100, ret_nyse*100],
index=["NYSE, NASDAQ & AMEX", "NYSE"])
data.columns = ["Premium"]
data.round(2)| Premium | |
|---|---|
| NYSE, NASDAQ & AMEX | 0.06 |
| NYSE | 0.15 |
The table shows that the size premium is more than 60 percent larger if we consider only stocks from NYSE to form the breakpoint each month. The NYSE-specific breakpoints are larger, and there are more than 50 percent of the stocks in the entire universe in the resulting small portfolio because NYSE firms are larger on average. The impact of this choice is not negligible.
P-Hacking and Non-Standard Errors
Since the choice of the listing exchange has a significant impact, the next step is to investigate the effect of other data processing decisions researchers have to make along the way. In particular, any portfolio sort analysis has to decide at least on the number of portfolios, the listing exchanges to form breakpoints, and equal- or value-weighting. Further, one may exclude firms that are active in the finance industry or restrict the analysis to some parts of the time series. All of the variations of these choices that we discuss here are part of scholarly articles published in the top finance journals. We refer to Walter, Weber, and Weiss (2022) for an extensive set of other decision nodes at the discretion of researchers.
The intention of this application is to show that the different ways to form portfolios result in different estimated size premiums. Despite the effects of this multitude of choices, there is no correct way. It should also be noted that none of the procedures is wrong. The aim is simply to illustrate the changes that can arise due to the variation in the evidence-generating process (Menkveld et al. 2021). The term non-standard errors refers to the variation due to (suitable) choices made by researchers. Interestingly, in a large-scale study, Menkveld et al. (2021) find that the magnitude of non-standard errors are similar to the estimation uncertainty based on a chosen model. This shows how important it is to adjust for the seemingly innocent choices in the data preparation and evaluation workflow. Moreover, it seems that this methodology-related uncertainty should be embraced rather than hidden away.
From a malicious perspective, these modeling choices give the researcher multiple chances to find statistically significant results. Yet this is considered p-hacking, which renders the statistical inference invalid due to multiple testing (Harvey, Liu, and Zhu 2016).
Nevertheless, the multitude of options creates a problem since there is no single correct way of sorting portfolios. How should a researcher convince a reader that their results do not come from a p-hacking exercise? To circumvent this dilemma, academics are encouraged to present evidence from different sorting schemes as robustness tests and report multiple approaches to show that a result does not depend on a single choice. Thus, the robustness of premiums is a key feature.
Below, we conduct a series of robustness tests, which could also be interpreted as a p-hacking exercise. To do so, we examine the size premium in different specifications presented in the table p_hacking_setup. The function itertools.product() produces all possible permutations of its arguments. Note that we use the argument data to exclude financial firms and truncate the time series.
n_portfolios = [2, 5, 10]
exchanges = [["NYSE"], ["NYSE", "NASDAQ", "AMEX"]]
value_weighted = [True, False]
data = [
crsp_monthly,
crsp_monthly[crsp_monthly["industry"] != "Finance"],
crsp_monthly[crsp_monthly["date"] < "1990-06-01"],
crsp_monthly[crsp_monthly["date"] >= "1990-06-01"],
]
p_hacking_setup = list(
product(n_portfolios, exchanges, value_weighted, data)
)To speed the computation up, we parallelize the (many) different sorting procedures, as in Beta Estimation using the joblib package. Finally, we report the resulting size premiums in descending order. There are indeed substantial size premiums possible in our data, in particular when we use equal-weighted portfolios.
n_cores = cpu_count()-1
p_hacking_results = pd.concat(
Parallel(n_jobs=n_cores)
(delayed(compute_portfolio_returns)(x, y, z, w)
for x, y, z, w in p_hacking_setup)
)
p_hacking_results = p_hacking_results.reset_index(name="size_premium")Size-Premium Variation
We provide a graph in Figure 3 that shows the different premiums. The figure also shows the relation to the average Fama-French SMB (small minus big) premium used in the literature, which we include as a dotted vertical line.
p_hacking_results_figure = (
ggplot(
p_hacking_results,
aes(x="size_premium")
)
+ geom_histogram(bins=len(p_hacking_results))
+ scale_x_continuous(labels=percent_format())
+ labs(
x="", y="",
title="Distribution of size premiums for various sorting choices"
)
+ geom_vline(
aes(xintercept=factors_ff3_monthly["smb"].mean()), linetype="dashed"
)
)
p_hacking_results_figure.show()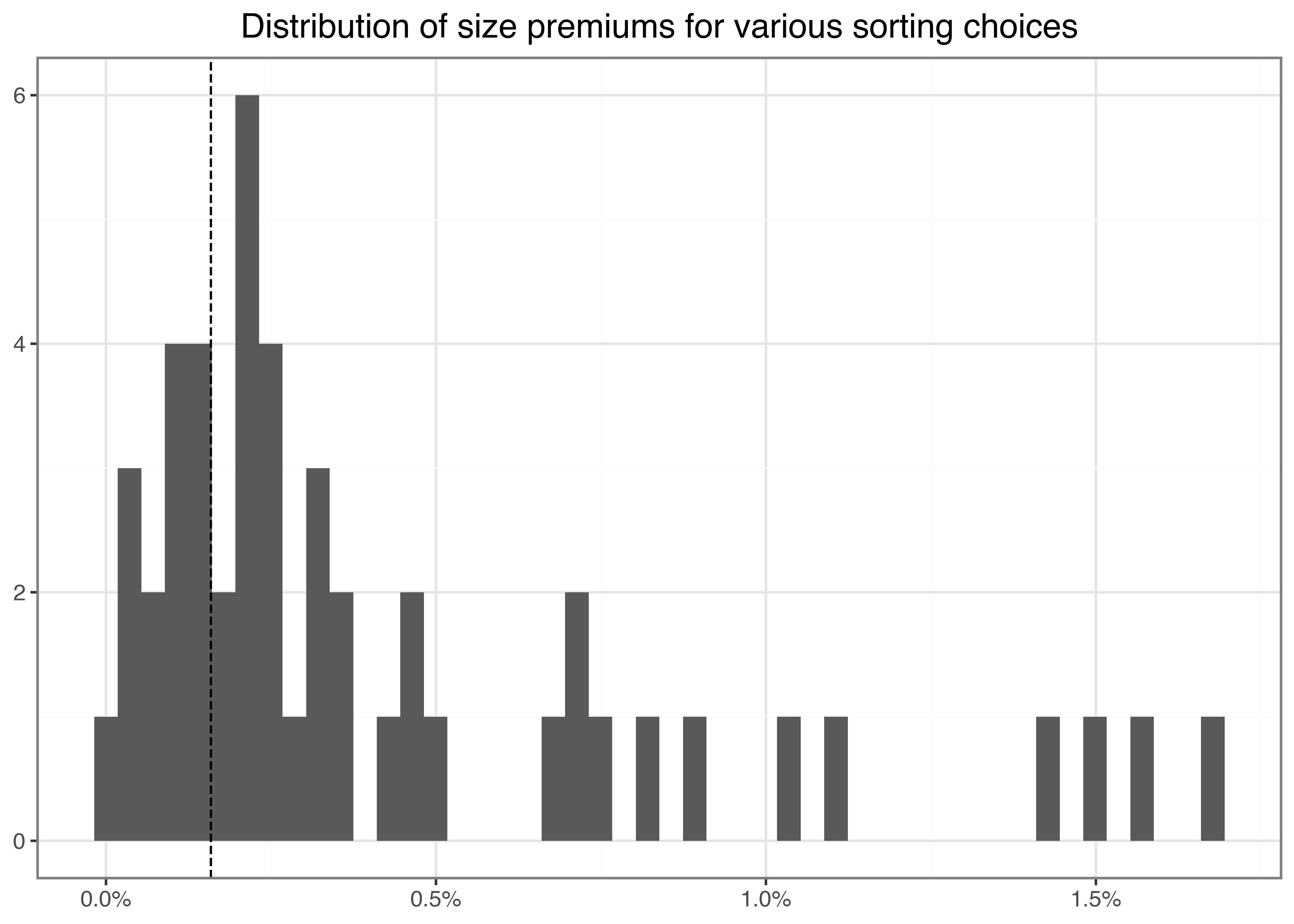
Key Takeaways
- Firm size is a crucial factor in asset pricing, and sorting stocks by size reveals the size premium, where small-cap stocks tend to outperform large-cap stocks.
- Portfolio returns are sensitive to research design choices like exchange filters, weighting schemes, and the number of portfolios—decisions that can meaningfully shift results.
- Methodological flexibility can lead to non-standard errors and potential p-hacking.
- Validate results by varying assumptions and show that findings hold across multiple specifications.
Exercises
- We gained several insights on the size distribution above. However, we did not analyze the average size across listing exchanges and industries. Which listing exchanges/industries have the largest firms? Plot the average firm size for the three listing exchanges over time. What do you conclude?
- We compute breakpoints but do not take a look at them in the exposition above. This might cover potential data errors. Plot the breakpoints for ten size portfolios over time. Then, take the difference between the two extreme portfolios and plot it. Describe your results.
- The returns that we analyze above do not account for differences in the exposure to market risk, i.e., the CAPM beta. Change the function
compute_portfolio_returns()to output the CAPM alpha or beta instead of the average excess return. - While you saw the spread in returns from the p-hacking exercise, we did not show which choices led to the largest effects. Find a way to investigate which choice variable has the largest impact on the estimated size premium.
- We computed several size premiums, but they do not follow the definition of Fama and French (1993). Which of our approaches comes closest to their SMB premium?
References
Fama, Eugene F., and Kenneth R. French. 1993. “Common risk factors in the returns on stocks and bonds.” Journal of Financial Economics 33 (1): 3–56. https://doi.org/10.1016/0304-405X(93)90023-5.
Harvey, Campbell R., Yan Liu, and Heqing Zhu. 2016. “\(\ldots\) and the cross-section of expected returns.” Review of Financial Studies 29 (1): 5–68. https://doi.org/10.1093/rfs/hhv059.
Hasler, Mathias. 2021. “Is the Value Premium Smaller Than We Thought?” Working Paper. https://ssrn.com/abstract=3886984.
Menkveld, Albert J., Anna Dreber, Felix Holzmeister, Juergen Huber, Magnus Johannesson, Michael Kirchler, Sebastian Neusüss, Michael Razen, and Utz Weitzel. 2021. “Non-standard errors.” Working Paper. https://papers.ssrn.com/sol3/papers.cfm?abstract\%5Fid=3961574.
Soebhag, Amar, Bart Van Vliet, and Patrick Verwijmeren. 2022. “Mind Your Sorts.” Working Paper. https://di.org/10.2139/ssrn.4136672.
Walter, Dominik, Rüdiger Weber, and Patrick Weiss. 2022. “Non-standard errors in portfolio sorts.” Working Paper. https://ssrn.com/abstract=4164117.