library(tidyverse)
library(tidyfinance)
library(scales)
library(RSQLite)
library(dbplyr)WRDS, CRSP, and Compustat
Note
You are reading Tidy Finance with R. You can find the equivalent chapter for the sibling Tidy Finance with Python here.
This chapter shows how to connect to Wharton Research Data Services (WRDS), a popular provider of financial and economic data for research applications. We use this connection to download the most commonly used data for stock and firm characteristics, CRSP and Compustat. Unfortunately, this data is not freely available, but most students and researchers typically have access to WRDS through their university libraries. Assuming that you have access to WRDS, we show you how to prepare and merge the databases and store them in the SQLite-database introduced in the previous chapter. We conclude this chapter by providing some tips for working with the WRDS database.
If you don’t have access to WRDS, but still want to run the code in this book, we refer to our blog post on Dummy Data for Tidy Finance Readers without Access to WRDS, where show how to create a dummy database that contains the WRDS tables and corresponding columns such that all code chunks in this book can be executed with this dummy database.
First, we load the R packages that we use throughout this chapter. Later on, we load more packages in the sections where we need them.
We use the same date range as in the previous chapter to ensure consistency.
start_date <- ymd("1960-01-01")
end_date <- ymd("2023-12-31")Accessing WRDS
WRDS is the most widely used source for asset and firm-specific financial data used in academic settings. WRDS is a data platform that provides data validation, flexible delivery options, and access to many different data sources. The data at WRDS is also organized in an SQL database, although they use the PostgreSQL engine. This database engine is just as easy to handle with R as SQLite. We use the RPostgres package to establish a connection to the WRDS database (Wickham, Ooms, and Müller 2022). Note that you could also use the odbc package to connect to a PostgreSQL database, but then you need to install the appropriate drivers yourself. RPostgres already contains a suitable driver.
library(RPostgres)To establish a connection to WRDS, you use the function dbConnect() with arguments that specify the WRDS server and your login credentials. We defined environment variables for the purpose of this book because we obviously do not want (and are not allowed) to share our credentials with the rest of the world. See Setting Up Your Environment for information about why and how to create an .Renviron-file. Alternatively, you can replace Sys.getenv("WRDS_USER") and Sys.getenv("WRDS_PASSWORD") with your own credentials (but be careful not to share them with others or the public).
Additionally, you have to use two-factor authentication since May 2023 when establishing a PostgreSQL or other remote connections. You have two choices to provide the additional identification. First, if you have Duo Push enabled for your WRDS account, you will receive a push notification on your mobile phone when trying to establish a connection with the code below. Upon accepting the notification, you can continue your work. Second, you can log in to a WRDS website that requires two-factor authentication with your username and the same IP address. Once you have successfully identified yourself on the website, your username-IP combination will be remembered for 30 days, and you can comfortably use the remote connection below.
wrds <- dbConnect(
Postgres(),
host = "wrds-pgdata.wharton.upenn.edu",
dbname = "wrds",
port = 9737,
sslmode = "require",
user = Sys.getenv("WRDS_USER"),
password = Sys.getenv("WRDS_PASSWORD")
)You can also use the tidyfinance package to set the login credentials and create a connection.
set_wrds_credentials()
wrds <- get_wrds_connection()The remote connection to WRDS is very useful. Yet, the database itself contains many different tables. You can check the WRDS homepage to identify the table’s name you are looking for (if you go beyond our exposition). Alternatively, you can also query the data structure with the function dbSendQuery(). If you are interested, there is an exercise below that is based on WRDS’ tutorial on “Querying WRDS Data using R”. Furthermore, the penultimate section of this chapter shows how to investigate the structure of databases.
Downloading and Preparing CRSP
The Center for Research in Security Prices (CRSP) provides the most widely used data for US stocks. We use the wrds connection object that we just created to first access monthly CRSP return data.1 Actually, we need two tables to get the desired data: (i) the CRSP monthly security file,
msf_db <- tbl(wrds, I("crsp.msf_v2"))and (ii) the identifying information,
stksecurityinfohist_db <- tbl(wrds, I("crsp.stksecurityinfohist"))We use the two remote tables to fetch the data we want to put into our local database. Just as above, the idea is that we let the WRDS database do all the work and just download the data that we actually need. We apply common filters and data selection criteria to narrow down our data of interest: (i) we use only stock prices from NYSE, Amex, and NASDAQ (primaryexch %in% c("N", "A", "Q")) when or after issuance (conditionaltype %in% c("RW", "NW")) for actively traded stocks (tradingstatusflg == "A")2, (ii) we keep only data in the time windows of interest, (iii) we keep only US-listed stocks as identified via no special share types (sharetype = 'NS'), security type equity (securitytype = 'EQTY'), security sub type common stock (securitysubtype = 'COM'), issuers that are a corporation (issuertype %in% c("ACOR", "CORP")), and (iv) we keep only months within permno-specific start dates (secinfostartdt) and end dates (secinfoenddt). As of July 2022, there is no need to additionally download delisting information since it is already contained in the most recent version of msf (see our blog post about CRSP 2.0 for more information). Additionally, the industry information in stksecurityinfohist records the historic industry and should be used instead of the one stored under same variable name in msf_v2.
crsp_monthly <- msf_db |>
filter(mthcaldt >= start_date & mthcaldt <= end_date) |>
select(-c(siccd, primaryexch, conditionaltype, tradingstatusflg)) |>
inner_join(
stksecurityinfohist_db |>
filter(sharetype == "NS" &
securitytype == "EQTY" &
securitysubtype == "COM" &
usincflg == "Y" &
issuertype %in% c("ACOR", "CORP") &
primaryexch %in% c("N", "A", "Q") &
conditionaltype %in% c("RW", "NW") &
tradingstatusflg == "A") |>
select(permno, secinfostartdt, secinfoenddt,
primaryexch, siccd),
join_by(permno)
) |>
filter(mthcaldt >= secinfostartdt & mthcaldt <= secinfoenddt) |>
mutate(date = floor_date(mthcaldt, "month")) |>
select(
permno, # Security identifier
date, # Month of the observation
ret = mthret, # Return
shrout, # Shares outstanding (in thousands)
prc = mthprc, # Last traded price in a month
primaryexch, # Primary exchange code
siccd # Industry code
) |>
collect() |>
mutate(
date = ymd(date),
shrout = shrout * 1000
)Now, we have all the relevant monthly return data in memory and proceed with preparing the data for future analyses. We perform the preparation step at the current stage since we want to avoid executing the same mutations every time we use the data in subsequent chapters.
The first additional variable we create is market capitalization (mktcap), which is the product of the number of outstanding shares (shrout) and the last traded price in a month (prc). Note that in contrast to returns (ret), these two variables are not adjusted ex-post for any corporate actions like stock splits. Therefore, if you want to use a stock’s price, you need to adjust it with a cumulative adjustment factor. We also keep the market cap in millions of USD just for convenience, as we do not want to print huge numbers in our figures and tables. In addition, we set zero market capitalization to missing as it makes conceptually little sense (i.e., the firm would be bankrupt).
crsp_monthly <- crsp_monthly |>
mutate(
mktcap = shrout * prc / 10^6,
mktcap = na_if(mktcap, 0)
)The next variable we frequently use is the one-month lagged market capitalization. Lagged market capitalization is typically used to compute value-weighted portfolio returns, as we demonstrate in a later chapter. The most simple and consistent way to add a column with lagged market cap values is to add one month to each observation and then join the information to our monthly CRSP data.
mktcap_lag <- crsp_monthly |>
mutate(date = date %m+% months(1)) |>
select(permno, date, mktcap_lag = mktcap)
crsp_monthly <- crsp_monthly |>
left_join(mktcap_lag, join_by(permno, date))If you wonder why we do not use the lag() function, e.g., via crsp_monthly |> group_by(permno) |> mutate(mktcap_lag = lag(mktcap)), take a look at the Exercises.
Next, we transform primary listing exchange codes to explicit exchange names.
crsp_monthly <- crsp_monthly |>
mutate(exchange = case_when(
primaryexch == "N" ~ "NYSE",
primaryexch == "A" ~ "AMEX",
primaryexch == "Q" ~ "NASDAQ",
.default = "Other"
))Similarly, we transform industry codes to industry descriptions following Bali, Engle, and Murray (2016). Notice that there are also other categorizations of industries (e.g., Fama and French 1997) that are commonly used.
crsp_monthly <- crsp_monthly |>
mutate(industry = case_when(
siccd >= 1 & siccd <= 999 ~ "Agriculture",
siccd >= 1000 & siccd <= 1499 ~ "Mining",
siccd >= 1500 & siccd <= 1799 ~ "Construction",
siccd >= 2000 & siccd <= 3999 ~ "Manufacturing",
siccd >= 4000 & siccd <= 4899 ~ "Transportation",
siccd >= 4900 & siccd <= 4999 ~ "Utilities",
siccd >= 5000 & siccd <= 5199 ~ "Wholesale",
siccd >= 5200 & siccd <= 5999 ~ "Retail",
siccd >= 6000 & siccd <= 6799 ~ "Finance",
siccd >= 7000 & siccd <= 8999 ~ "Services",
siccd >= 9000 & siccd <= 9999 ~ "Public",
.default = "Missing"
))Next, we compute excess returns by subtracting the monthly risk-free rate provided by our Fama-French data. As we base all our analyses on the excess returns, we can drop the risk-free rate from our tibble. Note that we ensure excess returns are bounded by -1 from below as a return less than -100 percent makes no sense conceptually. Before we can adjust the returns, we have to connect to our database and load the table factors_ff3_monthly.
tidy_finance <- dbConnect(
SQLite(),
"data/tidy_finance_r.sqlite",
extended_types = TRUE
)
factors_ff3_monthly <- tbl(tidy_finance, "factors_ff3_monthly") |>
select(date, rf) |>
collect()
crsp_monthly <- crsp_monthly |>
left_join(factors_ff3_monthly,
join_by(date)
) |>
mutate(
ret_excess = ret - rf,
ret_excess = pmax(ret_excess, -1)
) |>
select(-rf)The tidyfinance package provides a shortcut to implement all these processing steps from above.
crsp_monthly <- download_data(
type = "wrds_crsp_monthly",
start_date = start_date,
end_date = end_date
)Since excess returns and market capitalization are crucial for all our analyses, we can safely exclude all observations with missing returns or market capitalization.
crsp_monthly <- crsp_monthly |>
drop_na(ret_excess, mktcap, mktcap_lag)Finally, we store the monthly CRSP file in our database.
dbWriteTable(
tidy_finance,
"crsp_monthly",
value = crsp_monthly,
overwrite = TRUE
)First Glimpse of the CRSP Sample
Before we move on to other data sources, let us look at some descriptive statistics of the CRSP sample, which is our main source for stock returns.
Figure 1 shows the monthly number of securities by listing exchange over time. NYSE has the longest history in the data, but NASDAQ lists a considerably large number of stocks. The number of stocks listed on AMEX decreased steadily over the last couple of decades. By the end of 2023, there were 2556 stocks with a primary listing on NASDAQ, 1289 on NYSE, and 166 on AMEX.
crsp_monthly |>
count(exchange, date) |>
ggplot(aes(x = date, y = n, color = exchange, linetype = exchange)) +
geom_line() +
labs(
x = NULL, y = NULL, color = NULL, linetype = NULL,
title = "Monthly number of securities by listing exchange"
) +
scale_x_date(date_breaks = "10 years", date_labels = "%Y") +
scale_y_continuous(labels = comma)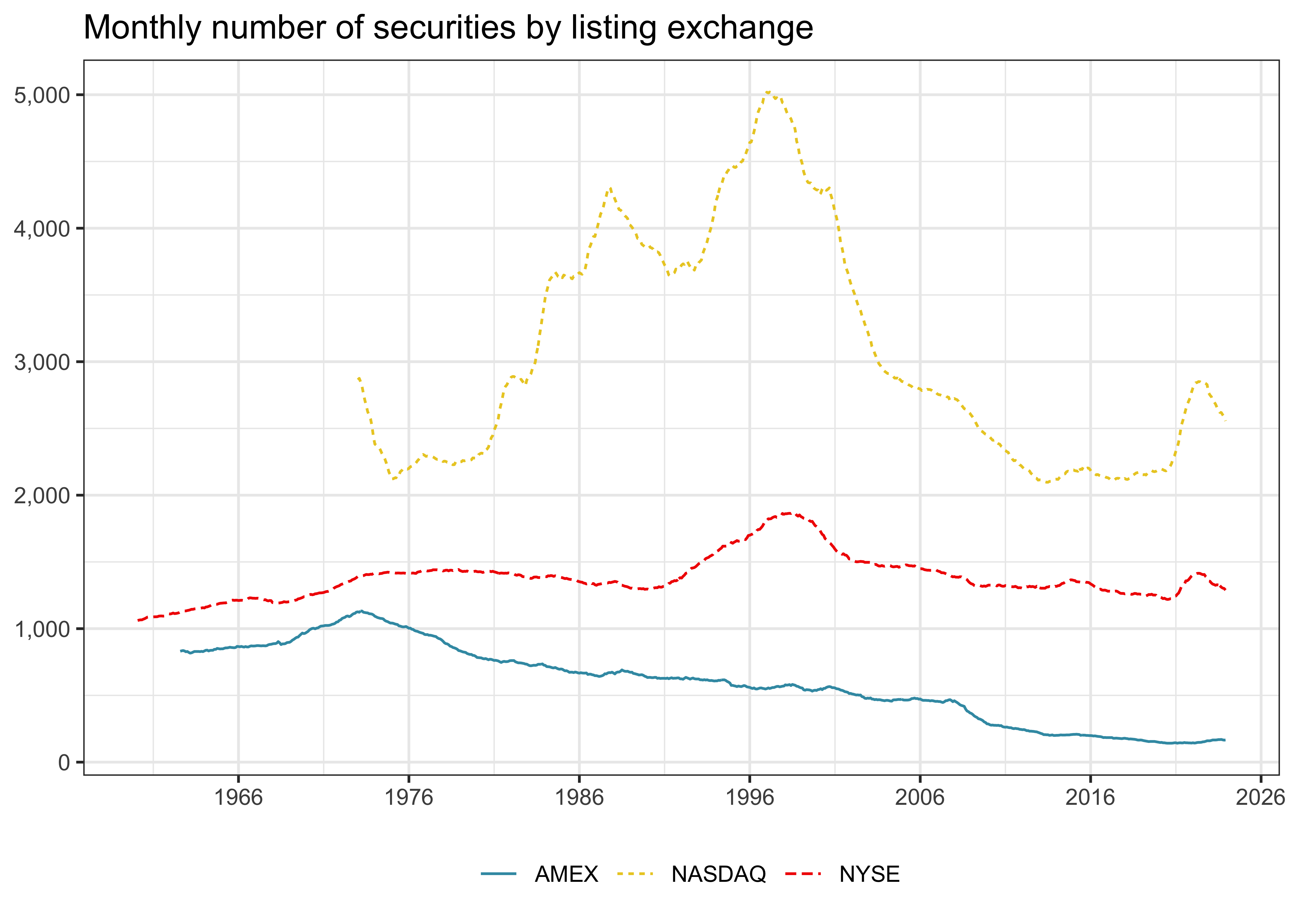
Next, we look at the aggregate market capitalization grouped by the respective listing exchanges in Figure 2. To ensure that we look at meaningful data which is comparable over time, we adjust the nominal values for inflation. In fact, we can use the tables that are already in our database to calculate aggregate market caps by listing exchange and plotting it just as if they were in memory. All values in Figure 2 are at the end of 2023 USD to ensure intertemporal comparability. NYSE-listed stocks have by far the largest market capitalization, followed by NASDAQ-listed stocks.
tbl(tidy_finance, "crsp_monthly") |>
left_join(tbl(tidy_finance, "cpi_monthly"), join_by(date)) |>
group_by(date, exchange) |>
summarize(
mktcap = sum(mktcap, na.rm = TRUE) / cpi,
.groups = "drop"
) |>
collect() |>
mutate(date = ymd(date)) |>
ggplot(aes(
x = date, y = mktcap / 1000,
color = exchange, linetype = exchange
)) +
geom_line() +
labs(
x = NULL, y = NULL, color = NULL, linetype = NULL,
title = "Monthly market cap by listing exchange in billions of Dec 2023 USD"
) +
scale_x_date(date_breaks = "10 years", date_labels = "%Y") +
scale_y_continuous(labels = comma)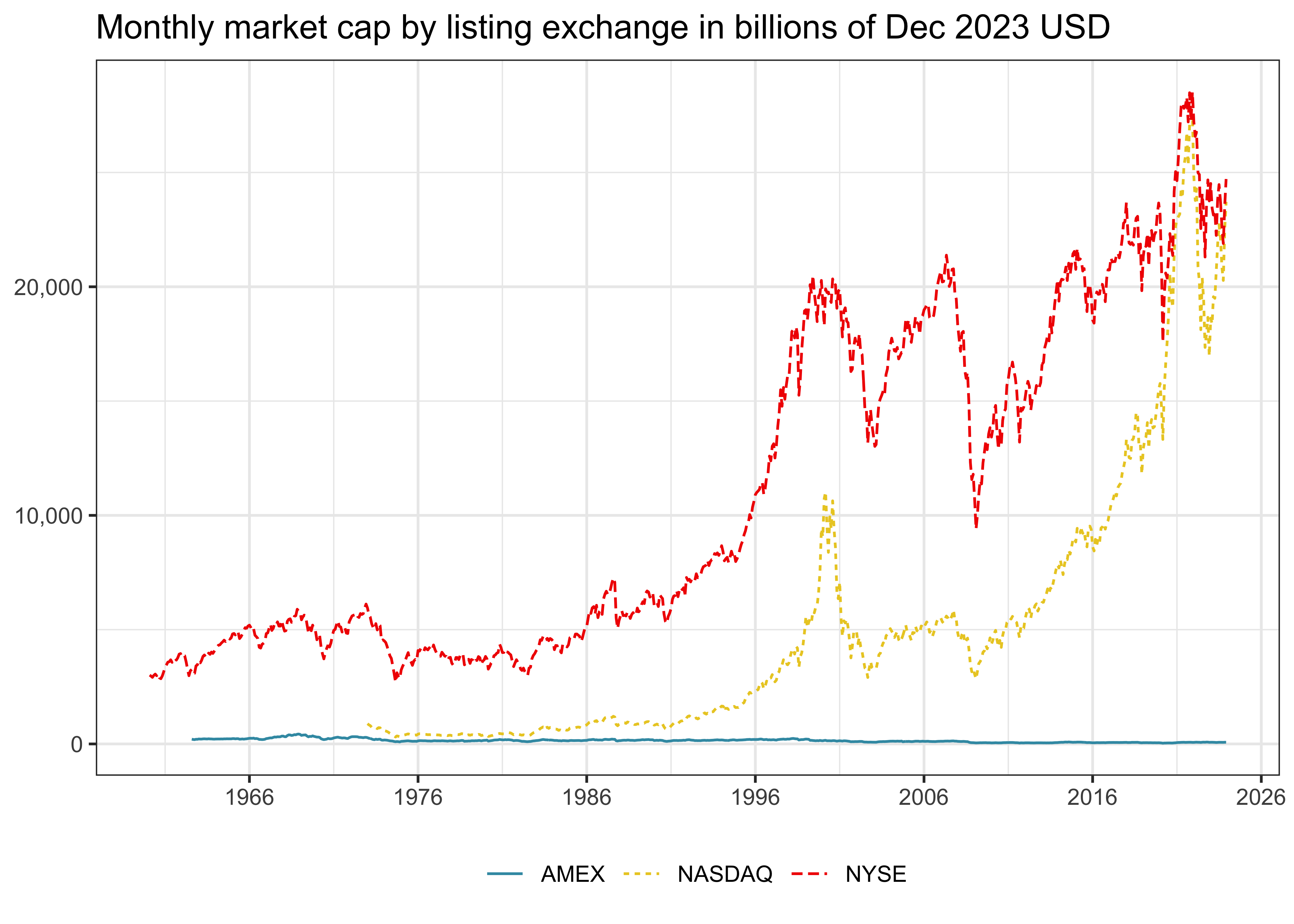
Of course, performing the computation in the database is not really meaningful because we can easily pull all the required data into our memory. The code chunk above is slower than performing the same steps on tables that are already in memory. However, we just want to illustrate that you can perform many things in the database before loading the data into your memory. Before we proceed, we load the monthly CPI data.
cpi_monthly <- tbl(tidy_finance, "cpi_monthly") |>
collect()Next, we look at the same descriptive statistics by industry. Figure 3 plots the number of stocks in the sample for each of the SIC industry classifiers. For most of the sample period, the largest share of stocks is in manufacturing, albeit the number peaked somewhere in the 90s. The number of firms associated with public administration seems to be the only category on the rise in recent years, even surpassing manufacturing at the end of our sample period.
crsp_monthly_industry <- crsp_monthly |>
left_join(cpi_monthly, join_by(date)) |>
group_by(date, industry) |>
summarize(
securities = n_distinct(permno),
mktcap = sum(mktcap) / mean(cpi),
.groups = "drop"
)
crsp_monthly_industry |>
ggplot(aes(
x = date,
y = securities,
color = industry,
linetype = industry
)) +
geom_line() +
labs(
x = NULL, y = NULL, color = NULL, linetype = NULL,
title = "Monthly number of securities by industry"
) +
scale_x_date(date_breaks = "10 years", date_labels = "%Y") +
scale_y_continuous(labels = comma)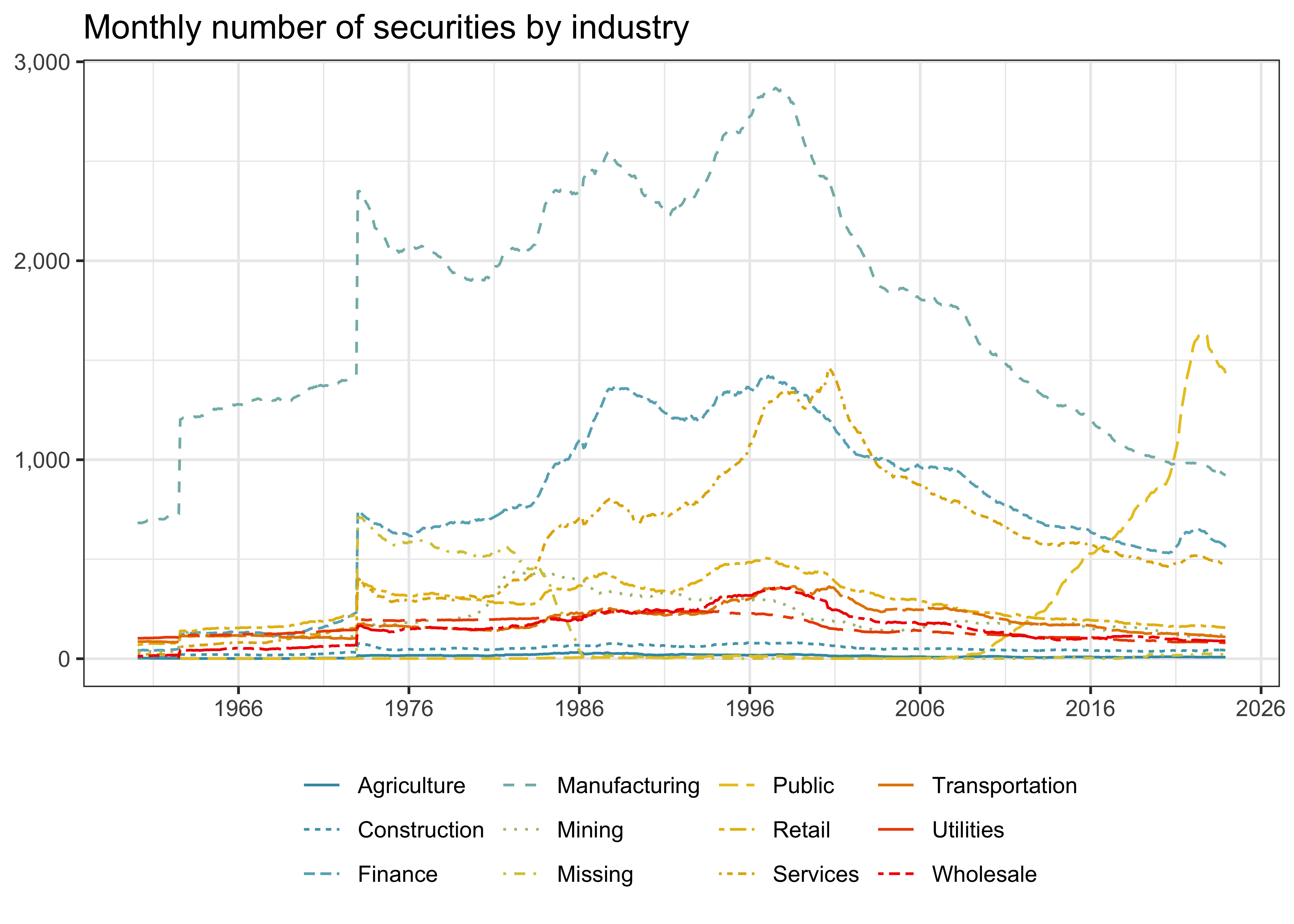
We also compute the market cap of all stocks belonging to the respective industries and show the evolution over time in Figure 4. All values are again in terms of billions of end of 2023 USD. At all points in time, manufacturing firms comprise of the largest portion of market capitalization. Toward the end of the sample, however, financial firms and services begin to make up a substantial portion of the market cap.
crsp_monthly_industry |>
ggplot(aes(
x = date,
y = mktcap / 1000,
color = industry,
linetype = industry
)) +
geom_line() +
labs(
x = NULL, y = NULL, color = NULL, linetype = NULL,
title = "Monthly total market cap by industry in billions as of Dec 2023 USD"
) +
scale_x_date(date_breaks = "10 years", date_labels = "%Y") +
scale_y_continuous(labels = comma)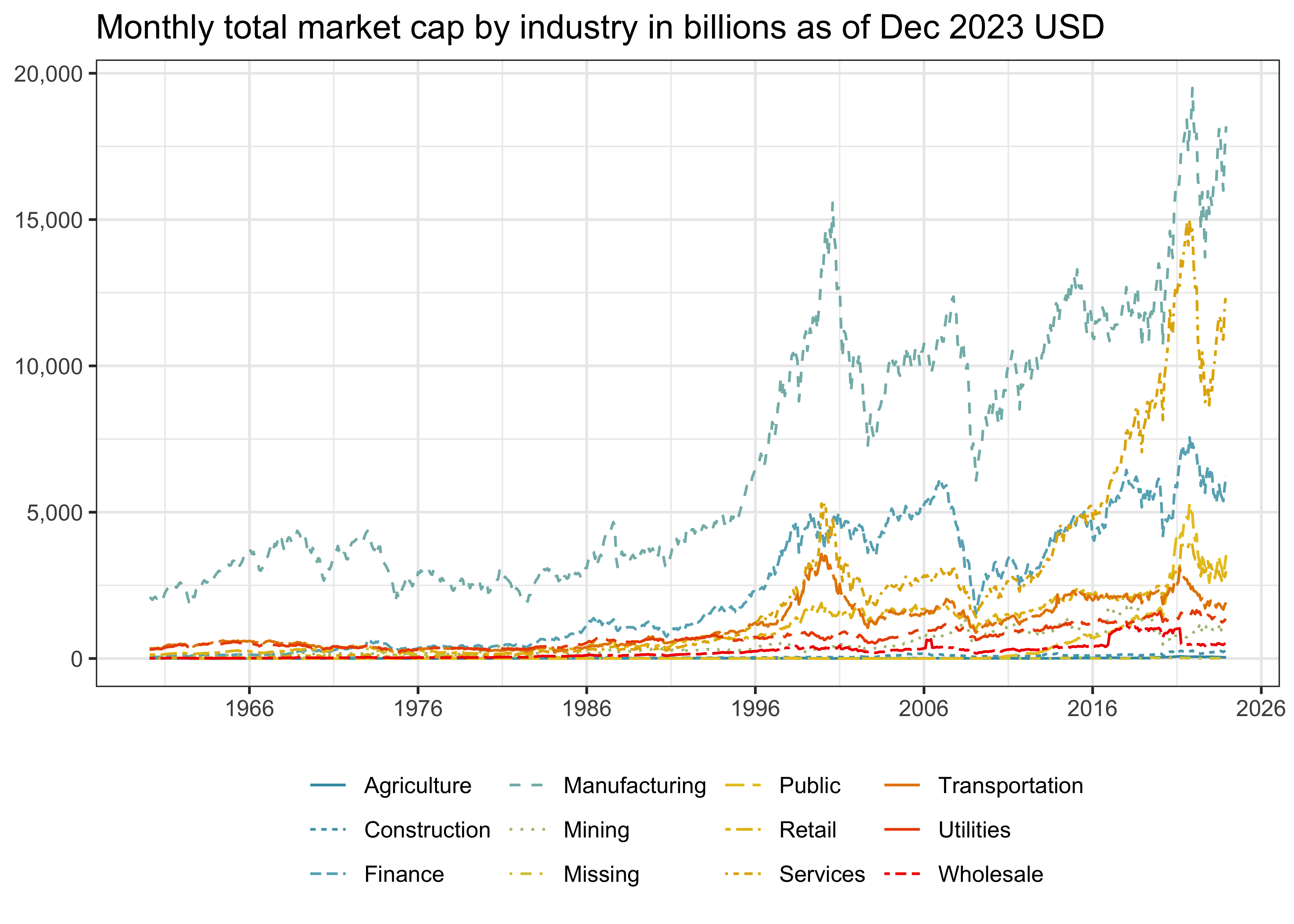
Daily CRSP Data
Before we turn to accounting data, we provide a proposal for downloading daily CRSP data with the same filters used for the monthly data (i.e., using information from stksecurityinfohist). While the monthly data from above typically fit into your memory and can be downloaded in a meaningful amount of time, this is usually not true for daily return data. The daily CRSP data file is substantially larger than monthly data and can exceed 20 GB. This has two important implications: you cannot hold all the daily return data in your memory (hence it is not possible to copy the entire dataset to your local database), and in our experience, the download usually crashes (or never stops) because it is too much data for the WRDS cloud to prepare and send to your R session.
There is a solution to this challenge. As with many big data problems, you can split up the big task into several smaller tasks that are easier to handle. That is, instead of downloading data about all stocks at once, download the data in small batches of stocks consecutively. Such operations can be implemented in for-loops, where we download, prepare, and store the data for a small number of stocks in each iteration. This operation might nonetheless take around 5 minutes, depending on your internet connection. To keep track of the progress, we create ad-hoc progress updates using message(). Notice that we also use the function dbWriteTable() here with the option to append the new data to an existing table, when we process the second and all following batches. As for the monthly CRSP data, there is no need to adjust for delisting returns in the daily CRSP data since July 2022.
dsf_db <- tbl(wrds, I("crsp.dsf_v2"))
stksecurityinfohist_db <- tbl(wrds, I("crsp.stksecurityinfohist"))
factors_ff3_daily <- tbl(tidy_finance, "factors_ff3_daily") |>
collect()
permnos <- stksecurityinfohist_db |>
distinct(permno) |>
pull(permno)
batch_size <- 500
batches <- ceiling(length(permnos) / batch_size)
for (j in 1:batches) {
permno_batch <- permnos[
((j - 1) * batch_size + 1):min(j * batch_size, length(permnos))
]
crsp_daily_sub <- dsf_db |>
filter(permno %in% permno_batch) |>
filter(dlycaldt >= start_date & dlycaldt <= end_date) |>
inner_join(
stksecurityinfohist_db |>
filter(sharetype == "NS" &
securitytype == "EQTY" &
securitysubtype == "COM" &
usincflg == "Y" &
issuertype %in% c("ACOR", "CORP") &
primaryexch %in% c("N", "A", "Q") &
conditionaltype %in% c("RW", "NW") &
tradingstatusflg == "A") |>
select(permno, secinfostartdt, secinfoenddt),
join_by(permno)
) |>
filter(dlycaldt >= secinfostartdt & dlycaldt <= secinfoenddt) |>
select(permno, date = dlycaldt, ret = dlyret) |>
collect() |>
drop_na()
if (nrow(crsp_daily_sub) > 0) {
crsp_daily_sub <- crsp_daily_sub |>
left_join(factors_ff3_daily |>
select(date, rf), join_by(date)) |>
mutate(
ret_excess = ret - rf,
ret_excess = pmax(ret_excess, -1)
) |>
select(permno, date, ret, ret_excess)
dbWriteTable(
tidy_finance,
"crsp_daily",
value = crsp_daily_sub,
overwrite = ifelse(j == 1, TRUE, FALSE),
append = ifelse(j != 1, TRUE, FALSE)
)
}
message("Batch ", j, " out of ", batches, " done (", percent(j / batches), ")\n")
}Eventually, we end up with more than 71 million rows of daily return data. Note that we only store the identifying information that we actually need, namely permno and date alongside the excess returns. We thus ensure that our local database contains only the data that we actually use.
To download the daily CRSP data via the tidyfinance package, you can call:
crsp_daily <- download_data(
type = "wrds_crsp_daily",
start_date = start_date,
end_date = end_date
)Note that you need at least 16 GB of memory to hold all the daily CRSP returns in memory. We hence recommend to use loop the function over different date periods and store the results.
Preparing Compustat Data
Firm accounting data are an important source of information that we use in portfolio analyses in subsequent chapters. The commonly used source for firm financial information is Compustat provided by S&P Global Market Intelligence, which is a global data vendor that provides financial, statistical, and market information on active and inactive companies throughout the world. For US and Canadian companies, annual history is available back to 1950 and quarterly as well as monthly histories date back to 1962.
To access Compustat data, we can again tap WRDS, which hosts the funda table that contains annual firm-level information on North American companies.
funda_db <- tbl(wrds, I("comp.funda"))We follow the typical filter conventions and pull only data that we actually need: (i) we get only records in industrial data format, which includes companies that are primarily involved in manufacturing, services, and other non-financial business activities,3 (ii) in the standard format (i.e., consolidated information in standard presentation), (iii) reported in USD,4 and (iv) only data in the desired time window.
compustat <- funda_db |>
filter(
indfmt == "INDL" &
datafmt == "STD" &
consol == "C" &
curcd == "USD" &
datadate >= start_date & datadate <= end_date
) |>
select(
gvkey, # Firm identifier
datadate, # Date of the accounting data
seq, # Stockholders' equity
ceq, # Total common/ordinary equity
at, # Total assets
lt, # Total liabilities
txditc, # Deferred taxes and investment tax credit
txdb, # Deferred taxes
itcb, # Investment tax credit
pstkrv, # Preferred stock redemption value
pstkl, # Preferred stock liquidating value
pstk, # Preferred stock par value
capx, # Capital investment
oancf, # Operating cash flow
sale, # Revenue
cogs, # Costs of goods sold
xint, # Interest expense
xsga # Selling, general, and administrative expenses
) |>
collect()Next, we calculate the book value of preferred stock and equity be and the operating profitability op inspired by the variable definitions in Ken French’s data library. Note that we set negative or zero equity to missing which is a common practice when working with book-to-market ratios (see Fama and French 1992 for details).
compustat <- compustat |>
mutate(
be = coalesce(seq, ceq + pstk, at - lt) +
coalesce(txditc, txdb + itcb, 0) -
coalesce(pstkrv, pstkl, pstk, 0),
be = if_else(be <= 0, NA, be),
op = (sale - coalesce(cogs, 0) -
coalesce(xsga, 0) - coalesce(xint, 0)) / be,
)We keep only the last available information for each firm-year group. Note that datadate defines the time the corresponding financial data refers to (e.g., annual report as of December 31, 2022). Therefore, datadate is not the date when data was made available to the public. Check out the exercises for more insights into the peculiarities of datadate.
compustat <- compustat |>
mutate(year = year(datadate)) |>
group_by(gvkey, year) |>
filter(datadate == max(datadate)) |>
ungroup()We also compute the investment ratio inv according to Ken French’s variable definitions as the change in total assets from one fiscal year to another. Note that we again use the approach using joins as introduced with the CRSP data above to construct lagged assets.
compustat <- compustat |>
left_join(
compustat |>
select(gvkey, year, at_lag = at) |>
mutate(year = year + 1),
join_by(gvkey, year)
) |>
mutate(
inv = at / at_lag - 1,
inv = if_else(at_lag <= 0, NA, inv)
)With the last step, we are already done preparing the firm fundamentals. Thus, we can store them in our local database.
dbWriteTable(
tidy_finance,
"compustat",
value = compustat,
overwrite = TRUE
)The tidyfinance package provides a shortcut for these processing steps as well:
compustat <- download_data(
type = "wrds_compustat_annual",
start_date = start_date,
end_date = end_date
)Merging CRSP with Compustat
Unfortunately, CRSP and Compustat use different keys to identify stocks and firms. CRSP uses permno for stocks, while Compustat uses gvkey to identify firms. Fortunately, a curated matching table on WRDS allows us to merge CRSP and Compustat, so we create a connection to the CRSP-Compustat Merged table (provided by CRSP).
ccm_linking_table_db <- tbl(wrds, I("crsp.ccmxpf_lnkhist"))The linking table contains links between CRSP and Compustat identifiers from various approaches. However, we need to make sure that we keep only relevant and correct links, again following the description outlined in Bali, Engle, and Murray (2016). Note also that currently active links have no end date, so we just enter the current date via today().
ccm_linking_table <- ccm_linking_table_db |>
filter(
linktype %in% c("LU", "LC") &
linkprim %in% c("P", "C")
) |>
select(permno = lpermno, gvkey, linkdt, linkenddt) |>
collect() |>
mutate(linkenddt = replace_na(linkenddt, today()))We use these links to create a new table with a mapping between stock identifier, firm identifier, and month. We then add these links to the Compustat gvkey to our monthly stock data.
ccm_links <- crsp_monthly |>
inner_join(ccm_linking_table,
join_by(permno), relationship = "many-to-many") |>
filter(!is.na(gvkey) &
(date >= linkdt & date <= linkenddt)) |>
select(permno, gvkey, date)To fetch these links via tidyfinance, you can call:
ccm_links <- download_data(type = "wrds_ccm_links")As the last step, we update the previously prepared monthly CRSP file with the linking information in our local database.
crsp_monthly <- crsp_monthly |>
left_join(ccm_links, join_by(permno, date))
dbWriteTable(
tidy_finance,
"crsp_monthly",
value = crsp_monthly,
overwrite = TRUE
)Before we close this chapter, let us look at an interesting descriptive statistic of our data. As the book value of equity plays a crucial role in many asset pricing applications, it is interesting to know for how many of our stocks this information is available. Hence, Figure 5 plots the share of securities with book equity values for each exchange. It turns out that the coverage is pretty bad for AMEX- and NYSE-listed stocks in the 1960s but hovers around 80 percent for all periods thereafter. We can ignore the erratic coverage of securities that belong to the other category since there is only a handful of them anyway in our sample.
crsp_monthly |>
group_by(permno, year = year(date)) |>
filter(date == max(date)) |>
ungroup() |>
left_join(compustat, join_by(gvkey, year)) |>
group_by(exchange, year) |>
summarize(
share = n_distinct(permno[!is.na(be)]) / n_distinct(permno),
.groups = "drop"
) |>
ggplot(aes(
x = year,
y = share,
color = exchange,
linetype = exchange
)) +
geom_line() +
labs(
x = NULL, y = NULL, color = NULL, linetype = NULL,
title = "Share of securities with book equity values by exchange"
) +
scale_y_continuous(labels = percent) +
coord_cartesian(ylim = c(0, 1))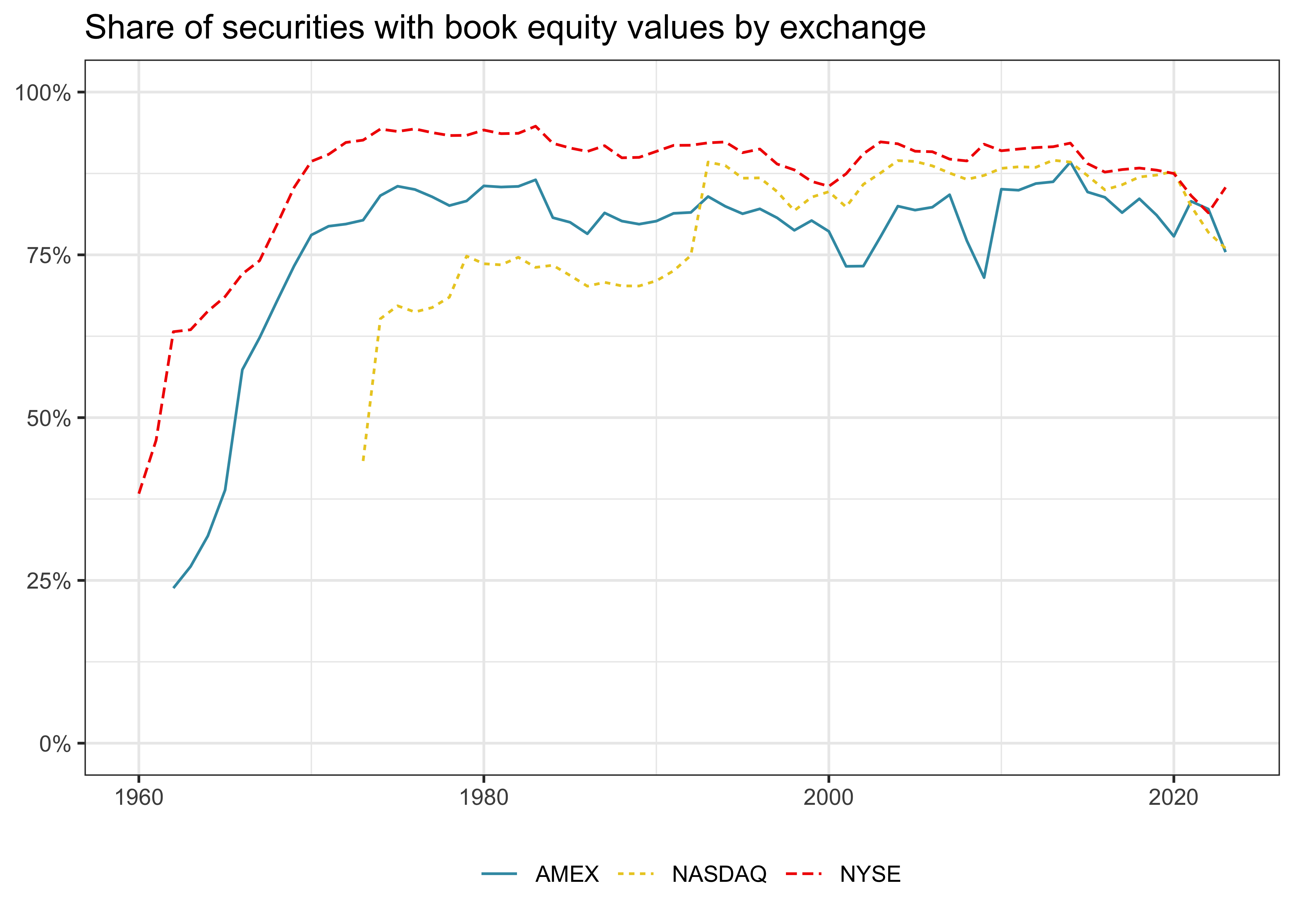
Some Tricks for PostgreSQL Databases
As we mentioned above, the WRDS database runs on PostgreSQL rather than SQLite. Finding the right tables for your data needs can be tricky in the WRDS PostgreSQL instance, as the tables are organized in schemas. If you wonder what the purpose of schemas is, check out this documetation. For instance, if you want to find all tables that live in the crsp schema, you run
dbListObjects(wrds, Id(schema = "crsp"))This operation returns a list of all tables that belong to the crsp family on WRDS, e.g., <Id> schema = crsp, table = msenames. Similarly, you can fetch a list of all tables that belong to the comp family via
dbListObjects(wrds, Id(schema = "comp"))If you want to get all schemas, then run
dbListObjects(wrds)Key Takeaways
- WRDS provides secure access to essential financial databases like CRSP and Compustat, which are critical for empirical finance research.
- CRSP data provides return, market capitalization and industry data for US common stocks listed on NYSE, NASDAQ, or AMEX.
- Compustat provides firm-level accounting data such as book equity, profitability, and investment.
- The
tidyfinanceR package streamlines all major data download and processing steps, making it easy to replicate and scale financial data analysis.
Exercises
- Check out the structure of the WRDS database by sending queries in the spirit of “Querying WRDS Data using R” and verify the output with
dbListObjects(). How many tables are associated with CRSP? Can you identify what is stored withinmsp500? - Compute
mkt_cap_lagusinglag(mktcap)rather than using joins as above. Filter out all the rows where the lag-based market capitalization measure is different from the one we computed above. Why are the two measures they different? - Plot the average market capitalization of firms for each exchange and industry, respectively, over time. What do you find?
- In the
compustattable,datadaterefers to the date to which the fiscal year of a corresponding firm refers. Count the number of observations in Compustat bymonthof this date variable. What do you find? What does the finding suggest about pooling observations with the same fiscal year? - Go back to the original Compustat data in
funda_dband extract rows where the same firm has multiple rows for the same fiscal year. What is the reason for these observations? - Keep the last observation of
crsp_monthlyby year and join it with thecompustattable. Create the following plots: (i) aggregate book equity by exchange over time and (ii) aggregate annual book equity by industry over time. Do you notice any different patterns to the corresponding plots based on market capitalization? - Repeat the analysis of market capitalization for book equity, which we computed from the Compustat data. Then, use the matched sample to plot book equity against market capitalization. How are these two variables related?
References
Bali, Turan G, Robert F Engle, and Scott Murray. 2016. Empirical asset pricing: The cross section of stock returns. John Wiley & Sons. https://doi.org/10.1002/9781118445112.stat07954.
Fama, Eugene F., and Kenneth R. French. 1992. “The cross-section of expected stock returns.” The Journal of Finance 47 (2): 427–65. https://doi.org/2329112.
———. 1997. “Industry Costs of Equity.” Journal of Financial Economics 43 (2): 153–93. https://doi.org/10.1016/s0304-405x(96)00896-3.
Wickham, Hadley, Jeroen Ooms, and Kirill Müller. 2022. RPostgres: Rcpp interface to PostgreSQL. https://CRAN.R-project.org/package=RPostgres.
Footnotes
The
tbl()function creates a lazy table in our R session based on the remote WRDS database. To look up specific tables, we use theI("schema_name.table_name")approach.↩︎These three criteria jointly replicate the filter
exchcd %in% c(1, 2, 3, 31, 32, 33)used for the legacy version of CRSP. If you do not want to include stocks at issuance, you can set theconditionaltype == "RW", which is equivalent to the restriction ofexchcd %in% c(1, 2, 3)with the old CRSP format.↩︎Companies that operate in the banking, insurance, or utilities sector typically report in different industry formats that reflect their specific regulatory requirements.↩︎
Compustat also contains reports in CAD, which can lead a currency mismatch, e.g., when relating book equity to market equity.↩︎