library(tidyverse)
library(RSQLite)
library(fixest)
library(broom)Difference in Differences
Note
You are reading Tidy Finance with R. You can find the equivalent chapter for the sibling Tidy Finance with Python here.
In this chapter, we illustrate the concept of difference in differences (DD) estimators by evaluating the effects of climate change regulation on the pricing of bonds across firms. DD estimators are typically used to recover the treatment effects of natural or quasi-natural experiments that trigger sharp changes in the environment of a specific group. Instead of looking at differences in just one group (e.g., the effect in the treated group), DD investigates the treatment effects by looking at the difference between differences in two groups. Such experiments are usually exploited to address endogeneity concerns (e.g., Roberts and Whited 2013). The identifying assumption is that the outcome variable would change equally in both groups without the treatment. This assumption is also often referred to as the assumption of parallel trends. Moreover, we would ideally also want a random assignment to the treatment and control groups. Due to lobbying or other activities, this randomness is often violated in (financial) economics.
In the context of our setting, we investigate the impact of the Paris Agreement (PA), signed on December 12, 2015, on the bond yields of polluting firms. We first estimate the treatment effect of the agreement using panel regression techniques that we discuss in Fixed Effects and Clustered Standard Errors. We then present two methods to illustrate the treatment effect over time graphically. Although we demonstrate that the treatment effect of the agreement is anticipated by bond market participants well in advance, the techniques we present below can also be applied to many other settings.
The approach we use here replicates the results of Seltzer, Starks, and Zhu (2022) partly. Specifically, we borrow their industry definitions for grouping firms into green and brown types. Overall, the literature on environmental, social, and governance (ESG) effects in corporate bond markets is already large but continues to grow (for recent examples, see, e.g., Halling, Yu, and Zechner (2021), Handler, Jankowitsch, and Pasler (2022), Huynh and Xia (2021), among many others).
The current chapter relies on this set of R packages.
Data Preparation
We use TRACE and Mergent FISD as data sources from our SQLite-database introduced in Accessing and Managing Financial Data and TRACE and FISD.
tidy_finance <- dbConnect(
SQLite(),
"data/tidy_finance_r.sqlite",
extended_types = TRUE
)
fisd <- tbl(tidy_finance, "fisd") |>
select(complete_cusip, maturity, offering_amt, sic_code) |>
collect() |>
drop_na()
trace_enhanced <- tbl(tidy_finance, "trace_enhanced") |>
select(cusip_id, trd_exctn_dt, rptd_pr, entrd_vol_qt, yld_pt)|>
collect() |>
drop_na()We start our analysis by preparing the sample of bonds. We only consider bonds with a time to maturity of more than one year to the signing of the PA, so that we have sufficient data to analyze the yield behavior after the treatment date. This restriction also excludes all bonds issued after the agreement. We also consider only the first two digits of the SIC industry code to identify the polluting industries (in line with Seltzer, Starks, and Zhu 2022).
treatment_date <- ymd("2015-12-12")
polluting_industries <- c(
49, 13, 45, 29, 28, 33, 40, 20,
26, 42, 10, 53, 32, 99, 37
)
bonds <- fisd |>
filter(offering_amt > 0) |>
mutate(
time_to_maturity = as.numeric(maturity - treatment_date) / 365,
sic_code = as.integer(substr(sic_code, 1, 2)),
log_offering_amt = log(offering_amt)
) |>
filter(time_to_maturity >= 1) |>
select(
cusip_id = complete_cusip,
time_to_maturity, log_offering_amt, sic_code
) |>
mutate(polluter = sic_code %in% polluting_industries)Next, we aggregate the individual transactions as reported in TRACE to a monthly panel of bond yields. We consider bond yields for a bond’s last trading day in a month. Therefore, we first aggregate bond data to daily frequency and apply common restrictions from the literature (see, e.g., Bessembinder et al. 2008). We weigh each transaction by volume to reflect a trade’s relative importance and avoid emphasizing small trades. Moreover, we only consider transactions with reported prices rptd_pr larger than 25 (to exclude bonds that are close to default) and only bond-day observations with more than five trades on a corresponding day (to exclude prices based on too few, potentially non-representative transactions).
trace_aggregated <- trace_enhanced |>
filter(rptd_pr > 25) |>
group_by(cusip_id, trd_exctn_dt) |>
summarize(
avg_yield = weighted.mean(yld_pt, entrd_vol_qt * rptd_pr),
trades = n(),
.groups = "drop"
) |>
drop_na(avg_yield) |>
filter(trades >= 5) |>
mutate(date = floor_date(trd_exctn_dt, "month")) |>
group_by(cusip_id, date) |>
slice_max(trd_exctn_dt) |>
ungroup() |>
select(cusip_id, date, avg_yield)By combining the bond-specific information from Mergent FISD for our bond sample with the aggregated TRACE data, we arrive at the main sample for our analysis.
bonds_panel <- bonds |>
inner_join(trace_aggregated, join_by(cusip_id), multiple = "all") |>
drop_na()Before we can run the first regression, we need to define the treated indicator, which is the product of the post_period (i.e., all months after the signing of the PA) and the polluter indicator defined above.
bonds_panel <- bonds_panel |>
mutate(post_period = date >= floor_date(treatment_date, "months")) |>
mutate(treated = polluter & post_period)As usual, we tabulate summary statistics of the variables that enter the regression to check the validity of our variable definitions.
bonds_panel |>
pivot_longer(
cols = c(avg_yield, time_to_maturity, log_offering_amt),
names_to = "measure"
) |>
group_by(measure) |>
summarize(
mean = mean(value),
sd = sd(value),
min = min(value),
q05 = quantile(value, 0.05),
q50 = quantile(value, 0.50),
q95 = quantile(value, 0.95),
max = max(value),
n = n(),
.groups = "drop"
)# A tibble: 3 × 9
measure mean sd min q05 q50 q95 max n
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 avg_yield 4.08 4.21 0.0595 1.27 3.38 8.10 128. 127523
2 log_offering_amt 13.3 0.823 4.64 12.2 13.2 14.5 16.5 127523
3 time_to_maturity 8.55 8.41 1.01 1.50 5.81 27.4 101. 127523Panel Regressions
The PA is a legally binding international treaty on climate change. It was adopted by 196 parties at COP 21 in Paris on December 12, 2015 and entered into force on November 4, 2016. The PA obliges developed countries to support efforts to build clean, climate-resilient futures. One may thus hypothesize that adopting climate-related policies may affect financial markets. To measure the magnitude of this effect, we first run an ordinary least square (OLS) regression without fixed effects where we include the treated, post_period, and polluter dummies, as well as the bond-specific characteristics log_offering_amt and time_to_maturity. This simple model assumes that there are essentially two periods (before and after the PA) and two groups (polluters and non-polluters). Nonetheless, it should indicate whether polluters have higher yields following the PA compared to non-polluters.
The second model follows the typical DD regression approach by including individual (cusip_id) and time (date) fixed effects. In this model, we do not include any other variables from the simple model because the fixed effects subsume them, and we observe the coefficient of our main variable of interest: treated.
model_without_fe <- feols(
avg_yield ~ treated + post_period + polluter +
log_offering_amt + time_to_maturity,
vcov = "iid",
data = bonds_panel
)
model_with_fe <- feols(
avg_yield ~ treated | cusip_id + date,
vcov = "iid",
data = bonds_panel
)
etable(
model_without_fe, model_with_fe,
coefstat = "tstat", digits = 3, digits.stats = 3
) model_without_fe model_with_fe
Dependent Var.: avg_yield avg_yield
Constant 10.7*** (57.0)
treatedTRUE 0.462*** (9.31) 0.983*** (29.5)
post_periodTRUE -0.174*** (-5.92)
polluterTRUE 0.481*** (15.3)
log_offering_amt -0.551*** (-39.0)
time_to_maturity 0.058*** (41.6)
Fixed-Effects: ----------------- ---------------
cusip_id No Yes
date No Yes
________________ _________________ _______________
VCOV type IID IID
Observations 127,523 127,523
R2 0.032 0.647
Within R2 -- 0.007
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Both models indicate that polluters have significantly higher yields after the PA than non-polluting firms. Note that the magnitude of the treated coefficient varies considerably across models.
Visualizing Parallel Trends
Even though the regressions above indicate that there is an impact of the PA on bond yields of polluters, the tables do not tell us anything about the dynamics of the treatment effect. In particular, the models provide no indication about whether the crucial parallel trends assumption is valid. This assumption requires that in the absence of treatment, the difference between the two groups is constant over time. Although there is no well-defined statistical test for this assumption, visual inspection typically provides a good indication.
To provide such visual evidence, we revisit the simple OLS model and replace the treated and post_period indicators with month dummies for each group. This approach estimates the average yield change of both groups for each period and provides corresponding confidence intervals. Plotting the coefficient estimates for both groups around the treatment date shows us the dynamics of our panel data.
model_without_fe_time <- feols(
avg_yield ~ polluter + date:polluter +
time_to_maturity + log_offering_amt,
vcov = "iid",
data = bonds_panel |>
mutate(date = factor(date))
)
model_without_fe_coefs <- tidy(model_without_fe_time) |>
filter(str_detect(term, "date")) |>
mutate(
date = ymd(substr(term, nchar(term) - 9, nchar(term))),
treatment = str_detect(term, "TRUE"),
ci_up = estimate + qnorm(0.975) * std.error,
ci_low = estimate + qnorm(0.025) * std.error
)
model_without_fe_coefs |>
ggplot(
aes(date,
color = treatment,
linetype = treatment,
shape = treatment
)) +
geom_vline(
aes(xintercept = floor_date(treatment_date, "month")),
linetype = "dashed"
) +
geom_hline(
aes(yintercept = 0),
linetype = "dashed"
) +
geom_errorbar(
aes(ymin = ci_low, ymax = ci_up),
alpha = 0.5
) +
guides(linetype = "none") +
geom_point(aes(y = estimate)) +
labs(
x = NULL,
y = "Yield",
shape = "Polluter?",
color = "Polluter?",
title = "Polluters respond stronger to Paris Agreement than green firms"
)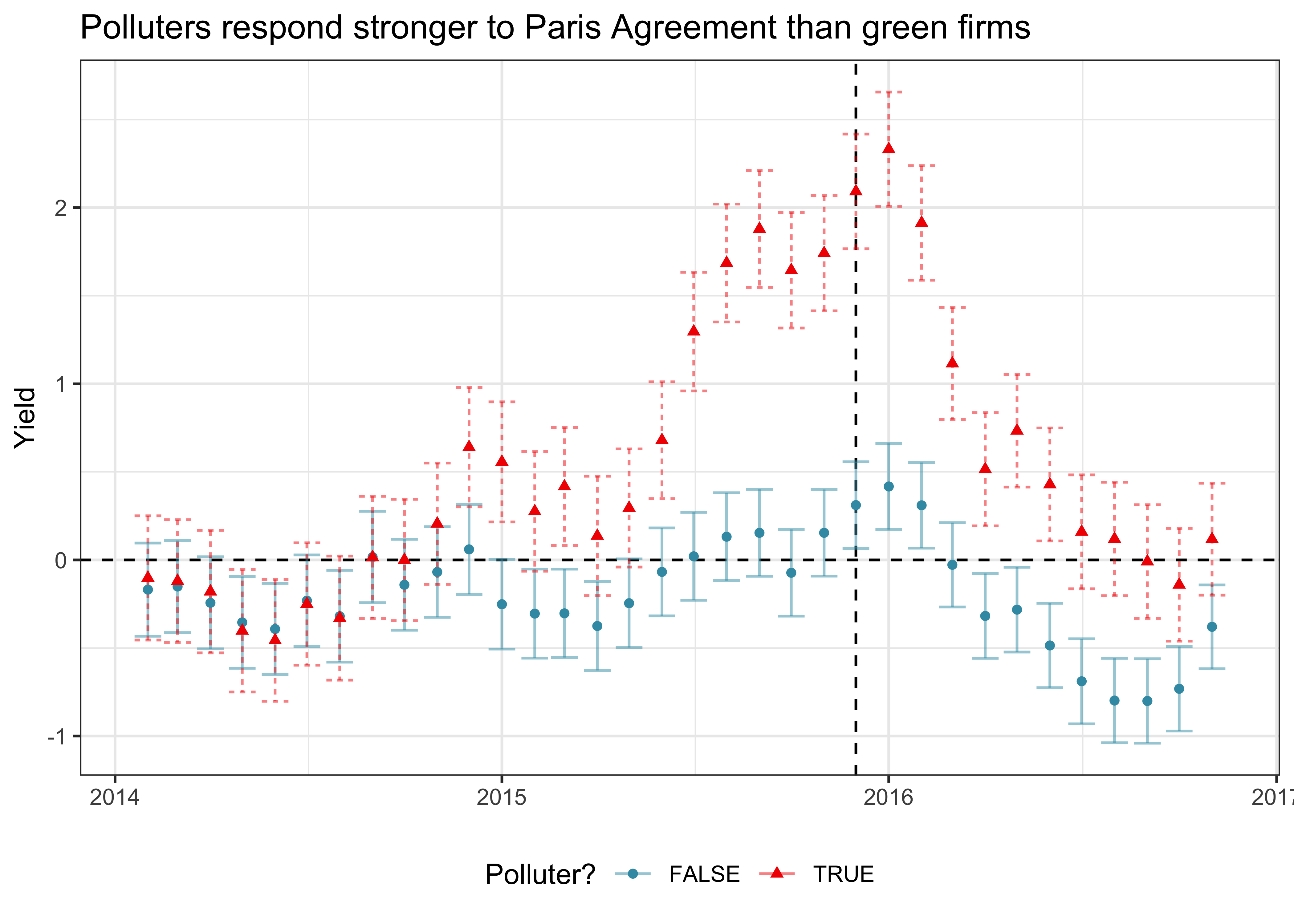
Figure 1 shows that throughout most of 2014, the yields of the two groups changed in unison. However, starting at the end of 2014, the yields start to diverge, reaching the highest difference around the signing of the PA. Afterward, the yields for both groups fall again, and the polluters arrive at the same level as at the beginning of 2014. The non-polluters, on the other hand, even experience significantly lower yields than polluters after the signing of the agreement.
Instead of plotting both groups using the simple model approach, we can also use the fixed-effects model and focus on the polluter’s yield response to the signing relative to the non-polluters. To perform this estimation, we need to replace the treated indicator with separate time dummies for the polluters, each marking a one-month period relative to the treatment date. We then regress the monthly yields on the set of time dummies and cusip_id and date fixed effects.
bonds_panel_alt <- bonds_panel |>
mutate(
diff_to_treatment = interval(
floor_date(treatment_date, "month"), date
) %/% months(1)
)
variables <- bonds_panel_alt |>
distinct(diff_to_treatment, date) |>
arrange(date) |>
mutate(variable_name = as.character(NA))
formula <- "avg_yield ~ "
for (j in 1:nrow(variables)) {
if (variables$diff_to_treatment[j] != 0) {
old_names <- names(bonds_panel_alt)
bonds_panel_alt <- bonds_panel_alt |>
mutate(new_var = diff_to_treatment == variables$diff_to_treatment[j] &
polluter)
new_var_name <- ifelse(variables$diff_to_treatment[j] < 0,
str_c("lag", abs(variables$diff_to_treatment[j])),
str_c("lead", variables$diff_to_treatment[j])
)
variables$variable_name[j] <- new_var_name
names(bonds_panel_alt) <- c(old_names, new_var_name)
formula <- str_c(
formula,
ifelse(j == 1,
new_var_name,
str_c("+", new_var_name)
)
)
}
}
formula <- str_c(formula, "| cusip_id + date")
model_with_fe_time <- feols(
as.formula(formula),
vcov = "iid",
data = bonds_panel_alt
)
model_with_fe_time_coefs <- tidy(model_with_fe_time) |>
mutate(
term = str_remove(term, "TRUE"),
ci_up = estimate + qnorm(0.975) * std.error,
ci_low = estimate + qnorm(0.025) * std.error
) |>
left_join(
variables,
join_by(term == variable_name)
) |>
bind_rows(tibble(
term = "lag0",
estimate = 0,
ci_up = 0,
ci_low = 0,
date = floor_date(treatment_date, "month")
))
model_with_fe_time_coefs |>
ggplot(aes(x = date, y = estimate)) +
geom_vline(
aes(xintercept = floor_date(treatment_date, "month")),
linetype = "dashed"
) +
geom_hline(
aes(yintercept = 0),
linetype = "dashed"
) +
geom_errorbar(
aes(ymin = ci_low, ymax = ci_up),
alpha = 0.5
) +
geom_point(aes(y = estimate)) +
labs(
x = NULL,
y = "Yield",
title = "Polluters' yield patterns around Paris Agreement signing"
)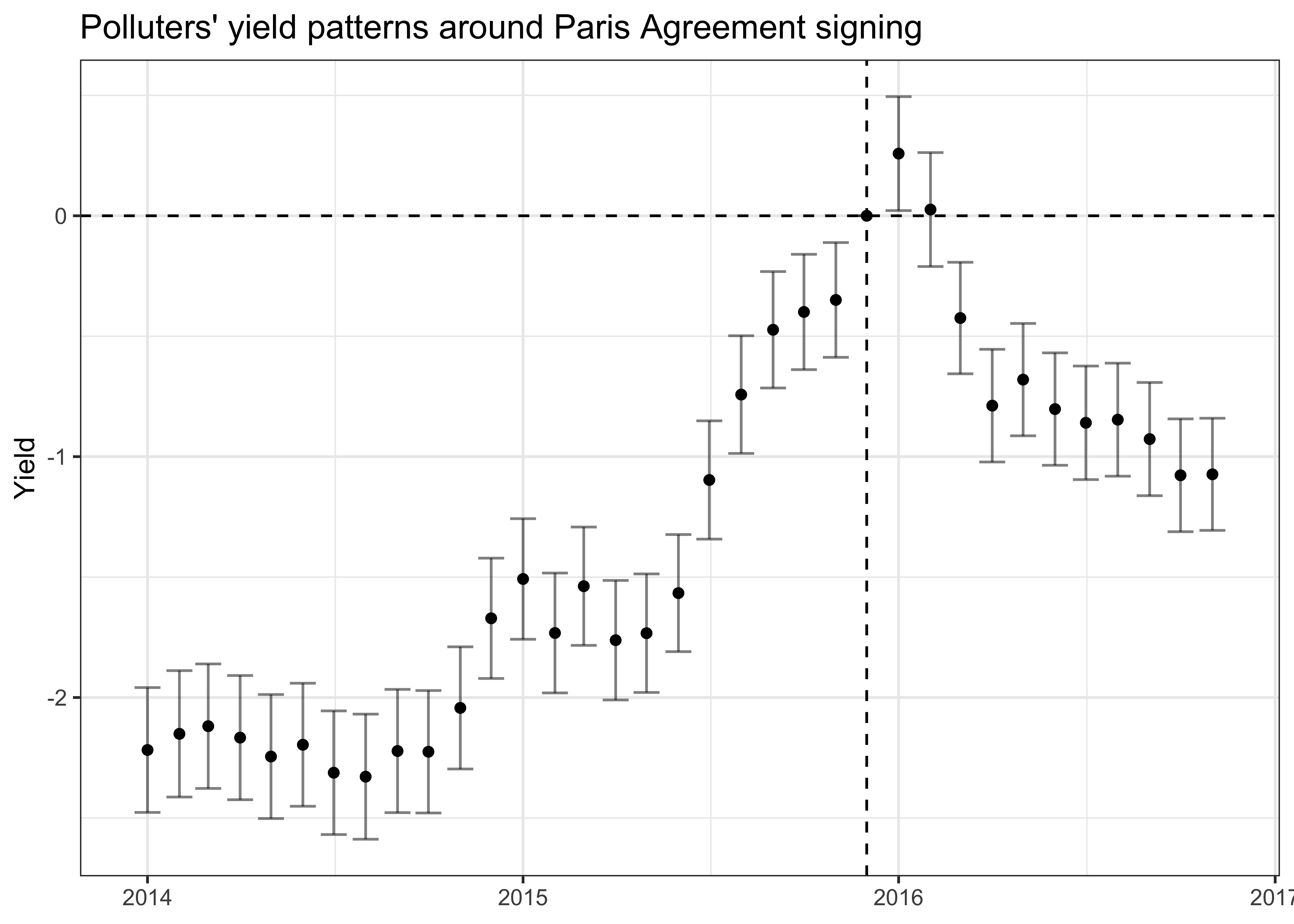
The resulting graph shown in Figure 2 confirms the main conclusion of the previous image: polluters’ yield patterns show a considerable anticipation effect starting toward the end of 2014. Yields only marginally increase after the signing of the agreement. However, as opposed to the simple model, we do not see a complete reversal back to the pre-agreement level. Yields of polluters stay at a significantly higher level even one year after the signing.
Notice that during the year after the PA was signed, Donald Trump, the 45th president of the United States, was elected on November 8, 2016. During his campaign there were some indications of intentions to withdraw the US from the PA, which ultimately happened on November 4, 2020. Hence, reversal effects are potentially driven by these actions.
Key Takeaways
- Difference-in-differences is a powerful tool for estimating causal effects in financial settings, especially when analyzing the impact of policy changes or shocks.
- It is important to assess the parallel trends assumption using graphical methods.
- The
fixestR package allows you to implement difference-in-differences regressions and visualize parallel trends. - By combining panel data from TRACE and Mergent FISD with fixed effects regressions, you can evaluate how the Paris Agreement influenced corporate bond yields.
- The application shows that polluting firms experienced significantly higher yields following up to and after the agreement, invalidating the parallel trends assumption.
Exercises
- The 46th President of the US, Joe Biden, rejoined the Paris Agreement on February 19, 2021. Repeat the difference in differences analysis for the day of his election victory. Note that you will also have to download new TRACE data. How did polluters’ yields react to this action?
- Based on the exercise on ratings in TRACE and FISD, include ratings as a control variable in the analysis above. Do the results change?
References
Bessembinder, Hendrik, Kathleen M Kahle, William F Maxwell, and Danielle Xu. 2008. “Measuring abnormal bond performance.” Review of Financial Studies 22 (10): 4219–58. https://doi.org/10.1093/rfs/hhn105.
Halling, Michael, Jin Yu, and Josef Zechner. 2021. “Primary Corporate Bond Markets and Social Responsibility.” Working Paper. https://dx.doi.org/10.2139/ssrn.3681666.
Handler, Lukas, Rainer Jankowitsch, and Alexander Pasler. 2022. “The Effects of ESG Performance and Preferences on US Corporate Bond Prices.” Working Paper. https://dx.doi.org/10.2139/ssrn.4099566.
Huynh, Thanh D., and Ying Xia. 2021. “Climate Change News Risk and Corporate Bond Returns.” Journal of Financial and Quantitative Analysis 56 (6): 1985–2009. https://doi.org/10.1017/S0022109020000757.
Roberts, Michael R., and Toni M. Whited. 2013. “Endogeneity in Empirical Corporate Finance.” In Handbook of the Economics of Finance, 2:493–572. Elsevier. https://EconPapers.repec.org/RePEc:eee:finchp:2-a-493-572.
Seltzer, Lee H., Laura Starks, and Qifei Zhu. 2022. “Climate Regulatory Risk and Corporate Bonds.” Working Paper. https://www.nber.org/papers/w29994.